

Verteiltes Lernen: KI nutzen, ohne die Datenhoheit zu verlieren
In unserem letzten Beitrag haben wir uns mit föderiertem Lernen beschäftigt. Dieser Ansatz ermöglicht es vielen unabhängigen Teilnehmern, ein gemeinsames Modell zu trainieren, ohne Rohdaten teilen zu müssen.
In diesem Beitrag weiten wir den Blick auf den übergeordneten Rahmen: Verteiltes Lernen (distributed learning). Dabei werden KI‑Modelle dort trainiert, wo Daten entstehen und dennoch kann über System‑ und Organisationsgrenzen hinweg ein leistungsfähiges, gemeinsames Modell aufgebaut werden.
Unternehmen stehen bei der Implementierung von Künstlicher Intelligenz (KI) vor einem komplexen Dilemma: Einerseits erfordern leistungsfähige KI-Modelle den Zugriff auf umfangreiche und heterogene Datensätze. Andererseits stellen Datenschutzbestimmungen, regulatorische Vorgaben und interne Governance-Mechanismen häufig erhebliche Hindernisse für die Etablierung zentraler Datenplattformen dar.
Verteiltes Lernen stellt eine vielversprechende Lösung für dieses Spannungsfeld dar. Das gilt insbesondere für regulierte, datenintensive Branchen wie Finanzdienstleistungen, Versicherungen und Industrieunternehmen, die mit sensiblen Produktions- und Kundendaten arbeiten.
Dieser Beitrag richtet sich an die Fachbereiche und Führungskräfte, die die Skalierung von KI-Anwendungen anstreben, ohne eine umfassende Neugestaltung ihrer Datenarchitektur vornehmen zu müssen.
Was ist Verteiltes Lernen?
Im Bereich des verteilten Lernens (englisch: distributed learning) erfolgt das Training von KI-Modellen nicht auf einem einzigen zentralen Server, sondern parallel auf mehreren, voneinander unabhängigen Systemen oder Endgeräten. Entscheidend ist hierbei, dass die zugrunde liegenden Rohdaten in den jeweiligen Quellsystemen verbleiben. Der Austausch beschränkt sich auf Modellparameter, Gradienten oder Konfigurationen.
Anstatt alle Daten zunächst in ein Data-Warehouse oder einen Lakehouse-Ansatz zu integrieren, wird das Modell zu den Daten gebracht. Lokale Instanzen des Modells werden dort trainiert, wo die Daten entstehen, beispielsweise in einem Fachbereichssystem, auf einem Edge-Gerät oder in einem separaten Rechenzentrum. Die lokalen Ergebnisse werden anschließend in ein übergreifendes, globales Modell zurückgeführt.
Ein vereinfachtes Ablaufdiagramm
- Definition eines zentralen Startmodells.
- Implementierung des Modells in die beteiligten Systeme oder Einheiten.
- Durchführung des lokalen Trainings auf den jeweiligen Datenbeständen.
- Übermittlung der Modellupdates (ohne Rohdaten) an eine zentrale Instanz.
- Aggregation und Aktualisierung des globalen Modells.
- Rückverteilung des optimierten Modells in die beteiligten Einheiten.
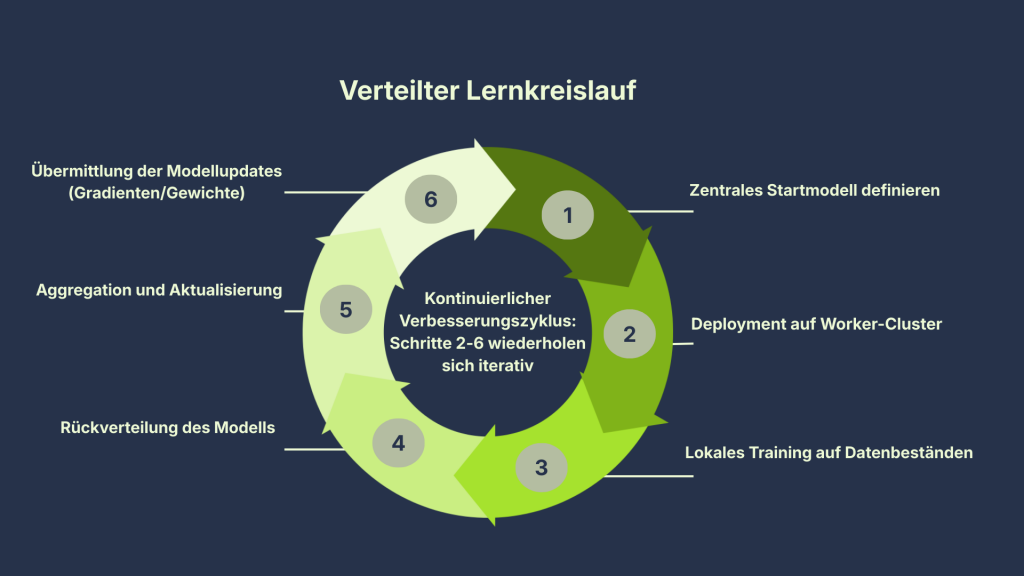
Der Prozess folgt einem iterativen Kreislauf: Ein Startmodell wird in die beteiligten Einheiten verteilt, dort lokal auf den vorhandenen Daten trainiert und anschließend über Modellupdates zentral konsolidiert. Auf diese Weise verbessert sich das globale Modell schrittweise, ohne dass Rohdaten zwischen den Einheiten ausgetauscht werden.
So entsteht ein Lernkreislauf, in dem alle Beteiligten von den Erfahrungen der anderen profitieren. Ihre sensiblen Daten müssen sie dabei nicht aus der Hand geben.
Warum verteiltes Lernen für Unternehmen relevant wird
Verteiltes Lernen gehört zu einer breiteren Klasse von Ansätzen, die häufig unter dem Begriff Privacy-Preserving AI zusammengefasst werden. Diese Methoden verfolgen das Ziel, KI-Modelle zu trainieren und auszuwerten, ohne sensible Daten zentralisieren oder offenlegen zu müssen.
Gerade in regulierten Branchen stehen Fachbereiche häufig vor der Herausforderung, KI-Anwendungsfälle zu implementieren, ohne auf den Abschluss umfangreicher zentraler Datenprojekte angewiesen zu sein.
Für Führungskräfte auf Management- und C-Level stellt sich gleichzeitig die Frage, wie sich KI-Initiativen unternehmensweit skalieren lassen, ohne die Kontrolle über Datenrisiken, Compliance und Governance zu verlieren.
Verteiltes Lernen bietet hier einen Ansatz, der beide Perspektiven miteinander verbindet.
Vorteile für Fachbereiche
1. Die Datenhoheit verbleibt im Fachbereich.
Fachbereiche behalten die Kontrolle über ihre operativen Daten und Zugriffe. Es ist nicht erforderlich, Daten in einen zentralen Data Lake zu migrieren, was bestehende Governance-Strukturen untergraben und die Implementierung neuer Abstimmungsprozesse erfordern würde.
2. Schnellere Umsetzung von Use-Cases
Da eine zentrale Datenintegration entfällt, können Fachbereiche zügig mit der Prototypenentwicklung beginnen und die produktive Nutzung beschleunigen. Bestehende Systeme, wie beispielsweise Kernbanksysteme, Schadenplattformen oder Produktionsleitsysteme, können unmittelbar als Datenquellen genutzt werden.
3. Nutzung bestehender Infrastruktur
Lokale Rechenkapazitäten, einschließlich Server innerhalb der Abteilung und Edge-Geräte, werden aktiv in den Trainingsprozess integriert. Dies reduziert die Abhängigkeit von zentralen Plattformen, die häufig unter Budgetbeschränkungen oder hoher Auslastung leiden.
Vorteile für Management und C‑Level
1. Risikoreduktion und Compliance
Da Rohdaten die jeweiligen Verantwortungsbereiche nicht verlassen, lassen sich Anforderungen aus Datenschutz, Aufsicht und Informationssicherheit besser erfüllen. Das reduziert regulatorische Risiken und vereinfacht Freigabeprozesse.
2. Skalierbarkeit über Organisationseinheiten hinweg
Verteiltes Lernen ermöglicht die Skalierung von KI-Initiativen über mehrere Einheiten, Länder oder Gesellschaften. Die Implementierung identischer Datenarchitekturen in allen Bereichen ist nicht erforderlich. Heterogene IT-Landschaften werden nicht als Hindernis betrachtet, sondern bewusst in die Planung integriert.
3. Optimierung des Return-on-Data (mehr Modelle aus bislang ungenutzten Datenquellen verbessern)
Daten, die bisher aufgrund von Governance- oder Sicherheitsanforderungen nicht zentralisiert werden konnten, können nun in die Verbesserung von Modellen integriert werden. Dies erhöht den Wertbeitrag bestehender Datenbestände, ohne neue Risiken einzuführen.
Typische Anwendungsfälle für verteiltes Lernen
Um das greifbar zu machen, drei typische Szenarien für erteiltes Lernen aus der Praxis.
1. Betrugserkennung im Finanzsektor
Verschiedene Einheiten, darunter Landesgesellschaften und Tochterbanken, verfügen über eigene Transaktionsdaten, die jeweils spezifische Kundenverhaltensweisen und Betrugsmuster aufweisen. Obwohl ein zentrales Modell wünschenswert wäre, stellt es aufgrund regulatorischer Vorgaben, der Datenlokalität oder interner Richtlinien eine Herausforderung dar.
Im Rahmen des verteilten Lernens trainiert jede Einheit lokal ein Modell zur Betrugserkennung auf ihren Transaktionsdaten. Die daraus resultierenden Modellupdates werden an eine zentrale Instanz übermittelt, die ein globales Modell ableitet und anschließend wieder verteilt. Jede Einheit profitiert so von einem erweiterten und diversifizierten Erfahrungsschatz, ohne sensible Transaktionsdaten preiszugeben.
2. Qualitätsüberwachung in der Industrie
In einem Produktionsverbund betreibt ein Unternehmen mehrere Werke mit ähnlichen, jedoch nicht identischen Anlagen. Jedes Werk erfasst Sensordaten und Qualitätskennzahlen, die aufgrund von Wettbewerbs-, Datenschutz- oder organisatorischen Gründen nicht ohne Weiteres zentralisiert werden können.
Verteiltes Lernen ermöglicht die Entwicklung eines gemeinsamen Modells zur Qualitätsprognose oder Anomalieerkennung. Jedes Werk trainiert das Modell lokal auf seinen Maschinendaten, wobei die Ergebnisse in ein globales Modell integriert werden. Dieses globale Modell berücksichtigt die Heterogenität der Produktionsumgebungen, ohne dass ein Austausch von Rohdaten erforderlich ist.
3. Kunden- und Vertriebsmodelle in Konzernverbünden
In Konzernstrukturen mit mehreren Marken oder Gesellschaften sind Kundendaten häufig fragmentiert. Gleichzeitig besteht der Wunsch, Cross-Selling-Potenziale, Next-Best-Action-Modelle sowie Abwanderungsprognosen konzernweit zu optimieren.
Durch Verteiltes Lernen können lokale Modelle innerhalb ihrer jeweiligen Gesellschaften trainiert werden. Die daraus resultierenden Modellupdates werden anschließend in ein übergreifendes Modell integriert. Dieses globale Modell kann für Analysen, Benchmarks oder konzernweite Services eingesetzt werden, ohne dass eine zentrale Zusammenführung der Kundendaten erforderlich ist.
Herausforderungen beim verteilten Lernen
Verteiltes Lernen ist kein Selbstläufer. Neben dem fachlichen Mehrwert müssen einige technische und organisatorische Punkte adressiert werden.
Technische Herausforderungen
1. Heterogene Systemlandschaft
Unterschiedliche Datenmodelle, Schnittstellen und Infrastrukturstandards erfordern eine klare Architektur und saubere Integrationskonzepte.
2. Kommunikationsaufwand und Performance
Der Austausch von Modellupdates über Netzwerkgrenzen hinweg erfordert eine effiziente Gestaltung unter Berücksichtigung von Latenz, Bandbreite und Sicherheitsanforderungen.
3. Monitoring und MLOps
Im Kontext verteilter Szenarien ist die Überwachung von Modellen, die Steuerung von Versionen und die Koordination von Retrainings unerlässlich. Hierzu bedarf es einer Erweiterung klassischer MLOps-Ansätze.
Organisatorische Herausforderungen
1. Klare Verantwortlichkeiten
Von entscheidender Bedeutung ist die klare Definition der Verantwortlichkeiten: Wer trägt die Verantwortung für das globale Modell? Wer ist für die lokalen Trainingsprozesse zuständig? Wie werden Konflikte gelöst, die sich aus divergierenden lokalen und globalen Optimierungszielen ergeben?
2. Governance und Richtlinien
Richtlinien für Datenzugriff, Modellnutzung, Logging und Audits müssen auf das verteilte Setting angepasst werden. Gerade in regulierten Branchen ist hier eine enge Kooperation von Fachbereich, IT, Compliance und Datenschutz notwendig.
3. Change-Management
Fachbereiche und lokale IT-Einheiten müssen sowohl technisch als auch kulturell befähigt werden, an verteilten Trainingsprozessen teilzunehmen. Transparente Kommunikation und klar definierte Mehrwerte sind für die Akzeptanz dieser Prozesse unerlässlich.
Föderiertes Lernen (Federated Learning) als Spezialfall
Föderiertes Lernen stellt eine spezialisierte Form des verteilten Lernens dar. Sie findet insbesondere in Szenarien mit einer Vielzahl an heterogenen Teilnehmern und hoher Datenschutzanforderungen Anwendung. Beispiele hierfür sind unter anderem Smartphones, IoT-Geräte sowie rechtlich eigenständige Organisationen.
- Eine erhebliche Heterogenität der Datenverteilungen und Datenqualitäten
- Teilnehmer, die nur zeitweise online verfügbar sind
- Die zwingende Vorgabe, dass Rohdaten ihren Ursprungsort bzw. Rechtsraum nicht verlassen dürfen
Föderiertes Lernen zeichnet sich durch folgende Merkmale aus:
In vielen Fällen ist föderiertes Lernen daher der geeignete Ansatz, wenn mehrere Unternehmen oder Organisationen gemeinsam ein Modell trainieren wollen, ohne ihre Daten gegenseitig offenzulegen. Eine vertiefende Einordnung dieser Ausprägung, einschließlich typischer Architekturen, regulatorischer Anforderungen und praktischer Anwendungsfelder, findet sich hier: Föderiertes Lernen im Detail.
Welcher Ansatz passt zu Ihrer Organisation? Ein strukturierter Readiness-Check zeigt, welche Use Cases, Daten und Governance-Strukturen sich für den Einstieg eignen. AI Federation unterstützt Sie dabei.
Weiterführende Quellen
Für eine vertiefende Auseinandersetzung mit dem Thema verteiltes Lernen empfehlen sich unter anderem die folgenden Quellen:
Fraunhofer IMS: Verteiltes Lernen
Fraunhofer HHI: DLFi – The Distributed Learning Framework
Verbraeken et al.: A Survey on Distributed Machine Learning – technischer Überblick zu Architekturen, Parallelisierung, Kommunikationsmustern und Systemdesign im verteilten maschinellen Lernen.












Schreiben Sie einen Kommentar