

Wenn Daten nicht einfach zusammengeführt werden können
Künstliche Intelligenz zählt im Finanzsektor längst zu den strategisch wichtigen Themen. In der Praxis beginnt die eigentliche Arbeit allerdings meist dort, wo es kompliziert wird: bei sensiblen Daten, gewachsenen Systemlandschaften und der kleinen Randnotiz, dass Regulierung leider nicht verschwindet, nur weil ein Use Case vielversprechend klingt.
Das Problem ist dabei oft nicht ein Mangel an Daten. Eher das Gegenteil, denn in vielen Instituten sind mehr als genug Informationen vorhanden. Sie sind nur eben verteilt über unterschiedliche Geschäftsbereiche, Systeme, Länder oder Organisationen. Genau das macht sie wertvoll, aber auch schwer nutzbar. Denn was fachlich zusammengehört, lässt sich regulatorisch und organisatorisch nicht einfach in einen Topf werfen, selbst wenn das aus Projektsicht gelegentlich verlockend erscheint.
Gemeinsam lernen, ohne Daten zu verschieben
An diesem Punkt werden neue Lernansätze interessant. Beim föderierten Lernen werden Modelle nicht auf einem einzigen zentralen Datenbestand trainiert, sondern direkt dort, wo die Daten ohnehin liegen. Ausgetauscht werden dabei nicht die Rohdaten selbst, sondern nur die Ergebnisse des Trainings beziehungsweise Modell-Updates. Vereinfacht gesagt: Die Daten bleiben an Ort und Stelle, und das Modell macht sich auf den Weg.
Gerade für den Finanzsektor ist das ein spannender Gedanke. Hier treffen hoher Erkenntnisbedarf und hohe Schutzanforderungen besonders direkt aufeinander. Risiken sollen frühzeitig erkannt, Betrug wirksam bekämpft und Prozesse intelligenter gestaltet werden. Gleichzeitig müssen Datenschutz, Vertraulichkeit, Governance und interne Kontrollmechanismen eingehalten werden. Das macht die Sache nicht unmöglich, aber eben etwas anspruchsvoller als die berühmte Folie mit dem Titel Einfach Skalieren.
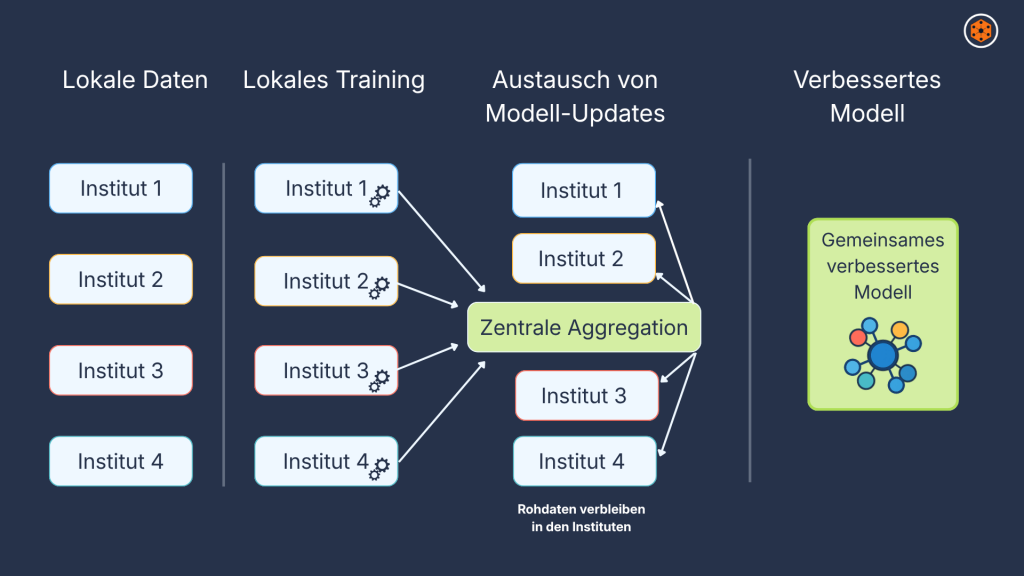
Abb. 1: Schematische Darstellung des föderierten Lernens im Finanzsektor: Daten bleiben lokal, Modell-Updates werden zentral aggregiert.
Wo der Ansatz besonders relevant wird
Hinzu kommt, dass viele interessante Anwendungsfälle gar nicht aus einem einzelnen Datensatz heraus entstehen. Relevante Muster zeigen sich oft erst dann, wenn Informationen aus unterschiedlichen Einheiten zusammengedacht werden. Das gilt etwa für Geldwäsche, Fraud Detection, Anomalieerkennung oder bestimmte Formen der Risikomodellierung. Genau dort stoßen klassische zentrale Datenansätze schnell an Grenzen: Die Zusammenarbeit wäre sinnvoll, der Austausch sensibler Daten bleibt aber heikel.
Föderiertes Lernen verspricht hier einen anderen Weg. Der Vorteil liegt nicht nur im Datenschutz, sondern auch in der Möglichkeit, kontrollierte Zusammenarbeit technisch besser abzubilden. Mehrere Einheiten oder Institutionen können an einem gemeinsamen Modell mitwirken, ohne ihre Datenbasis vollständig offenzulegen. Das ist kein Zaubertrick und auch keine elegante Abkürzung an jeder Governance vorbei, aber es ist ein Ansatz, der sehr gut zu regulierten Umgebungen passt.
Was dabei trotzdem zu beachten ist
Wichtig ist allerdings eine nüchterne Einordnung. Lernen ohne Datenaustausch bedeutet nicht automatisch, dass alle Datenschutz- oder Sicherheitsfragen gelöst sind. Auch Modell-Updates können Informationen preisgeben, wenn Schutzmechanismen fehlen oder die Architektur zu naiv gedacht ist. Wer föderiertes Lernen ernsthaft einsetzen will, braucht deshalb mehr als eine gute Idee: nämlich ein solides Zusammenspiel aus Technologie, Sicherheitsmaßnahmen, Governance und klaren Verantwortlichkeiten.
Genau darin liegt die eigentliche strategische Relevanz. Es geht nicht nur um ein weiteres KI-Verfahren, sondern um die Frage, wie sich leistungsfähige Modelle unter realen Bedingungen überhaupt sinnvoll betreiben lassen. Für Banken, Asset Manager, Versicherer und andere regulierte Akteure ist das keine Nebensache. Es entscheidet mit darüber, ob aus KI mehr wird als ein gut gemeinter Piloteinsatz, oder eben doch nur der nächste Innovationsbegriff mit schönem Foliensatz.
Lernen ohne Datenaustausch ist deshalb kein Spezialthema für Technikteams, sondern ein ernstzunehmender Baustein für den praktischen KI-Einsatz in regulierten Umgebungen. Wer heute über tragfähige KI-Architekturen im Finanzsektor nachdenkt, kommt an Datensouveränität, kontrollierter Kollaboration und belastbaren Betriebsmodellen kaum noch vorbei.
Leseliste
- AI Federation: Föderiertes Lernen: Ein neuer Ansatz für KI
- NIST: Privacy Attacks in Federated Learning
- NIST: Protecting Trained Models in Privacy-Preserving Federated Learning
- IBM Research: Building privacy-preserving federated learning to help fight financial crime
- Lucinity: Federated Learning for secure data sharing in FinCrime












Schreiben Sie einen Kommentar